MNIST with PyTorch¶
7/3/2020
PyTorch is another python machine learning library similar to scikit-learn. PyTorch is designed for deep learning, giving it more flexibility when creating neural networks.
Logistic Regression¶
Begin with imports:
import torch
from torch import nn, optim
from torch.utils.data import random_split
import torch.nn.functional as F
import torchvision
from torchvision import datasets, transforms
from ray import tune
import matplotlib.pyplot as plt
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('png')
import seaborn as sn
import pandas as pd
import numpy as np
import time
from livelossplot import PlotLosses
The full MNIST dataset is split into training (42000), validation (18000), and test (10000) sets. A batch size of 64 is also defined for stochastic gradient descent:
torch.manual_seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))]) #[-1,1]
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainset, valset = random_split(trainset, [42000,18000])
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
valloader = torch.utils.data.DataLoader(valset, batch_size=64, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
dataloaders = {'train':trainloader, 'validation':valloader}
Let’s show all digits in a single batch:
def imshow(img):
img = img / 2 + 0.5 #unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
plt.suptitle('MNIST Examples')
imshow(torchvision.utils.make_grid(images))

We define logistic regression as a two-layer neural net (784 input nodes for pixels, 10 output nodes for digit classification):
class LogReg(nn.Module):
def __init__(self):
super(LogReg, self).__init__()
self.linear = nn.Linear(784, 10)
def forward(self, x):
out = self.linear(x)
return out
Use a grid search to optimize learning rate:
def trainable_logreg(config):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = LogReg()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=config["lr"])
for epoch in range(10):
model.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs = inputs.view(inputs.shape[0], -1)
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.detach() * inputs.size(0)
tune.report(mean_loss=running_loss/len(trainloader.dataset))
tune.run(trainable_logreg, config={"lr": tune.grid_search([0.01, 0.03, 0.1])}, verbose=1)
Memory usage on this node: 8.6/23.9 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/8 CPUs, 0/0 GPUs, 0.0/9.77 GiB heap, 0.0/3.37 GiB objects
Result logdir: C:\Users\jl208\ray_results\trainable_logreg
Number of trials: 3 (3 TERMINATED)
| Trial name | status | loc | lr | loss | iter | total time (s) |
|---|---|---|---|---|---|---|
| trainable_logreg_4bda0_00000 | TERMINATED | 0.01 | 0.305648 | 10 | 172.208 | |
| trainable_logreg_4bda0_00001 | TERMINATED | 0.03 | 0.282862 | 10 | 170.787 | |
| trainable_logreg_4bda0_00002 | TERMINATED | 0.1 | 0.318506 | 10 | 172.697 |
<ray.tune.analysis.experiment_analysis.ExperimentAnalysis at 0x19951a446c8>
Train the model using stochastic gradient descent. To evaluate the classifier’s capabilities, we can we plot the accuracy and loss for training and validation sets as functions of the number of training epochs. After training, we can evaluate the model with the test set:
def train_model(model, criterion, optimizer, num_epochs, reshape, path):
time_start = time.clock()
best_val_loss = float('inf')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
liveloss = PlotLosses()
model = model.to(device)
for epoch in range(num_epochs):
logs = {}
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
if reshape:
inputs = inputs.view(inputs.shape[0],-1)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.detach() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.float() / len(dataloaders[phase].dataset)
prefix = ''
if phase == 'validation':
prefix = 'val_'
if epoch_loss < best_val_loss:
best_val_loss = epoch_loss
torch.save(model, path)
logs[prefix + 'log loss'] = epoch_loss.item()
logs[prefix + 'accuracy'] = epoch_acc.item()
liveloss.update(logs)
liveloss.send()
# evaluating best model on test set
model = torch.load(path)
test_loss = 0.0
test_corrects = 0
for inputs, labels in testloader:
if reshape:
inputs = inputs.view(inputs.shape[0],-1)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
test_loss += loss.detach() * inputs.size(0)
test_corrects += torch.sum(preds == labels.data)
test_loss = test_loss / len(testloader.dataset)
test_acc = test_corrects.float() / len(testloader.dataset)
print('Training time: %.3fs' % round(time.clock()-time_start,3))
print('Test loss: %.3f' % test_loss)
print('Test accuracy: %.3f%%' % (test_acc*100))
model=LogReg()
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.03)
num_epochs=20
train_model(model, criterion, optimizer, num_epochs, reshape=True, path='mnist_pytorch_logreg.pt')
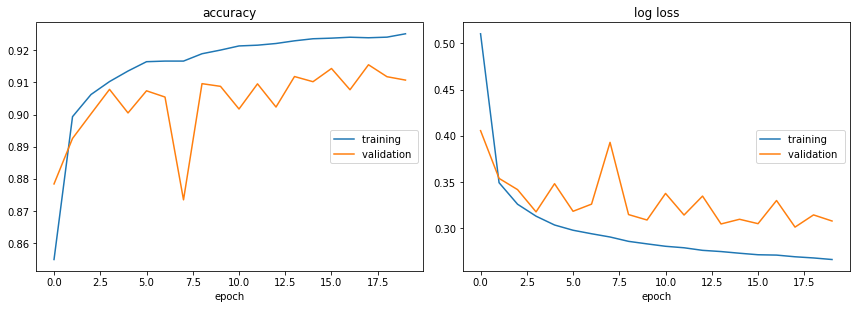
accuracy
training (min: 0.855, max: 0.925, cur: 0.925)
validation (min: 0.873, max: 0.915, cur: 0.911)
log loss
training (min: 0.266, max: 0.511, cur: 0.266)
validation (min: 0.301, max: 0.406, cur: 0.308)
Training time: 467.424s
Test loss: 0.284
Test accuracy: 92.160%
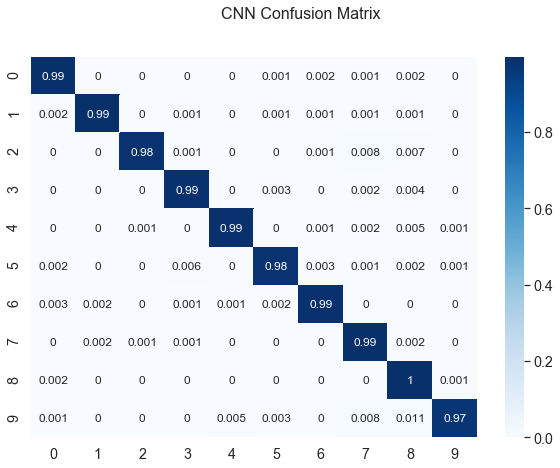
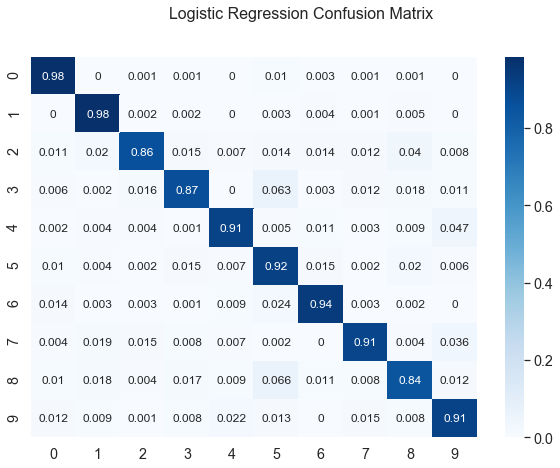
We can also plot a confusion matrix to see the classifier’s accuracy for different digits:
def confusion_matrix(model,name,reshape):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
cm = torch.zeros(10, 10)
with torch.no_grad():
for i, (inputs, labels) in enumerate(testloader):
if reshape:
inputs = inputs.view(inputs.shape[0],-1)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for t, p in zip(labels.view(-1), preds.view(-1)):
cm[t.long(), p.long()] += 1
cm = cm.numpy()
for i in range(10):
cm[i] = cm[i]/np.sum(cm[i])
cm = np.around(cm,3)
plt.figure(figsize=(10,7))
df_cm = pd.DataFrame(cm, range(10), range(10))
sn.set(font_scale=1.3)
sn.heatmap(df_cm, annot=True, annot_kws={'size': 12}, cmap='Blues')
plt.suptitle(name + ' Confusion Matrix', fontsize=16)
plt.show()
confusion_matrix(model,'Logistic Regression',reshape=True)
Multilayer Perceptron¶
We define a MLP with two hidden layers, one with 128 nodes and the other with 64 nodes. Similar to logistic regression, there are 784 input nodes and 10 output nodes:
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.hidden_1 = nn.Linear(784,128)
self.hidden_2 = nn.Linear(128,64)
self.output = nn.Linear(64,10)
def forward(self,x):
x = F.relu(self.hidden_1(x))
x = F.relu(self.hidden_2(x))
out = self.output(x)
return out
def trainable_mlp(config):
time_start = time.clock()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=config['lr'])
for epoch in range(10):
model.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs = inputs.view(inputs.shape[0], -1)
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.detach() * inputs.size(0)
tune.report(mean_loss=running_loss/len(trainloader.dataset))
print('Tuning time: %.3fs' % round(time.clock()-time_start,3))
tune.run(trainable_mlp, config={'lr': tune.grid_search([0.01, 0.03, 0.1])}, verbose=1)
(pid=8108) Tuning time: 167.976s
Memory usage on this node: 8.6/23.9 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/8 CPUs, 0/0 GPUs, 0.0/9.77 GiB heap, 0.0/3.37 GiB objects
Result logdir: C:\Users\jl208\ray_results\trainable_mlp
Number of trials: 3 (3 TERMINATED)
| Trial name | status | loc | lr | loss | iter | total time (s) |
|---|---|---|---|---|---|---|
| trainable_mlp_d8b07_00000 | TERMINATED | 0.01 | 0.226144 | 10 | 167.678 | |
| trainable_mlp_d8b07_00001 | TERMINATED | 0.03 | 0.101972 | 10 | 166.59 | |
| trainable_mlp_d8b07_00002 | TERMINATED | 0.1 | 0.0530744 | 10 | 167.97 |
<ray.tune.analysis.experiment_analysis.ExperimentAnalysis at 0x19a90a50948>
model=MLP()
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.1)
num_epochs=20
train_model(model, criterion, optimizer, num_epochs, reshape=True, path='mnist_pytorch_mlp.pt')
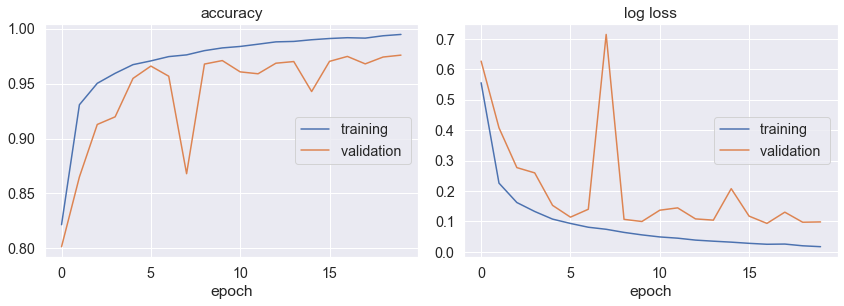
accuracy
training (min: 0.822, max: 0.995, cur: 0.995)
validation (min: 0.802, max: 0.976, cur: 0.976)
log loss
training (min: 0.017, max: 0.555, cur: 0.017)
validation (min: 0.093, max: 0.714, cur: 0.098)
Training time: 460.631s
Test loss: 0.081
Test accuracy: 97.660%
confusion_matrix(model,'MLP',reshape=True)

Convolutional Neural Network¶
We define a CNN with two convolution layers, each with 5x5 kernels. We have a max-pooling layer with stride 2 after each convolutional layer. Flattened tensors are then passed throung a dense layer and MLP:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self,x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = x.reshape(-1, 12*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.out(x)
return x
def trainable_cnn(config):
time_start = time.clock()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=config['lr'])
for epoch in range(5):
model.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.detach() * inputs.size(0)
tune.report(mean_loss=running_loss/len(trainloader.dataset))
print('Tuning time: %.3fs' % round(time.clock()-time_start,3))
tune.run(trainable_cnn, config={'lr': tune.grid_search([0.01, 0.03, 0.1])}, verbose=1)
Memory usage on this node: 8.8/23.9 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/8 CPUs, 0/0 GPUs, 0.0/9.77 GiB heap, 0.0/3.37 GiB objects
Result logdir: C:\Users\jl208\ray_results\trainable_cnn
Number of trials: 3 (3 TERMINATED)
| Trial name | status | loc | lr | loss | iter | total time (s) |
|---|---|---|---|---|---|---|
| trainable_cnn_5da4c_00000 | TERMINATED | 0.01 | 0.147092 | 5 | 194.109 | |
| trainable_cnn_5da4c_00001 | TERMINATED | 0.03 | 0.0657198 | 5 | 198.405 | |
| trainable_cnn_5da4c_00002 | TERMINATED | 0.1 | 0.0405428 | 5 | 196.356 |
<ray.tune.analysis.experiment_analysis.ExperimentAnalysis at 0x199521ca808>
model=CNN()
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.1)
num_epochs=10
train_model(model, criterion, optimizer, num_epochs, reshape=False, path='mnist_pytorch_cnn.pt')
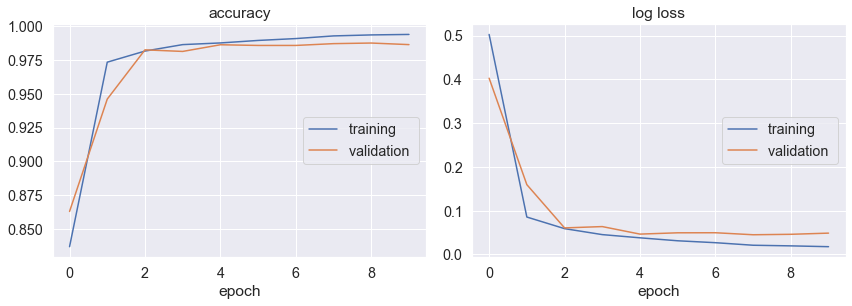
accuracy
training (min: 0.837, max: 0.994, cur: 0.994)
validation (min: 0.863, max: 0.988, cur: 0.987)
log loss
training (min: 0.018, max: 0.502, cur: 0.018)
validation (min: 0.045, max: 0.403, cur: 0.049)
Training time: 356.850s
Test loss: 0.031
Test accuracy: 99.020%
confusion_matrix(model,'CNN',reshape=False)